이전 글 – Data-driven Venture Capital – 을 쓰고 나서 이것저것 살펴보다가 발견한 Chahat Jain(2018)의 MIT 석사 학위 청구 논문 ‘Artificial Intelligence in Venture Capital Industry: Opportunities and Risks’를 읽게 됐다.
물론 인공지능이야 계속 핫한 분야였지만 GPT의 등장으로 AI 도입, 특히 업무에의 도입과 대체 가능성에 대한 논의가 급물살을 탄 것은 최근의 일인데, 2018년 2월 논문이라니.
논문은 ‘머신러닝이 최고의 투자처를 선정하는 것 뿐만 아니라 VC와 공동 투자자의 수익 극대화, 전략과 운영 지침 제공에도 사용될 수 있다’는 언급으로 시작한다. 연구의 목적은 VC가 AI 도구와 기법을 어떻게 활용할 수 있는지에 대한 것이라고.
AI 와 관련한 연구는 스타트업의 성공에 어떤 관계가 있는지에 주로 집중해왔지만 VC에 대한 정량적 접근을 시도한 연구는 드물기도 했다. 서두에 쓰인 저자의 말에 의하면 저자는 VC 업의 경험이 없는 사람이고, 최근 링크드인을 확인해보니 IT 기업들을 거치며 PM으로 근무하고 있는 것 같다.
논문 시점에서 저자가 파악한 현황들
DDVC 뉴스레터가 가장 최신의 현황들을 파악하고 있고 본 논문에서 언급된 사례들은 좀 더 outdated된 정보이기는 하지만, 이러한 정량적 툴을 VC업계에서 활용하는 것의 계보를 그린다면 필요할 것으로 보여 Memo차원에서 남겨두자면 다음과 같다.
(개인적으로는 이 파트도 그렇고, VC업예 대해서 설명한 파트에 나온 포트폴리오사에 Value add하는 방향성과 특징적인 하우스들에 대한 소개를 보고 적잖이 놀랐다. 이 논문을 접하지 못한 상태에서 사내에 작성해 보고했던 (일부는 외부에 릴리즈된) 리포트와 너무 비슷했기 떄문.)
- Google Ventures: 투자 결정을 돕기 위한 정량적 알고리즘 활용
- SignalFIre: 스타트업에 대한 자본 흐름과 주요 직원 이동을 모니터링 하는 등 독점 데이터베이스 저장소를 실시간 마이닝, 투자 대상 파악과 벤처 투자 결정 지원
- Corelation Ventures: 공동투자자로서 거래 참여에 관한 의사 결정을 위해 독점적 데이터 분석과 예측 컴퓨팅 도입. 미국 내 지난 20년 간의 VC 자금 조달에 대한 데이터베이스를 구축. ML 모델이 아닌 정교한 독점 예측 분석 모델을 통해 의사결정을 개선하고, 모든 투자에 이 모델을 사용함. 2주 내에 투자 의사결정함.
- Hone Capital: 중국 PE CSC 그룹의 미국 VC arm. 독점적인 데이터 기반 인텔리전스 플랫폼 구축
- Data Collective: 심사역 외에도 50명의 엔지니어 및 과학자로 구성된 독특한 조직 구조를 가진 곳
비즈니스에서 AI 도입의 중요성
저자는 AI 얼리어답터와 다른 기업간의 격차가 점점 커지고 있다며, 디지털 역량과 전략을 결합한 기업이 더 나은 성과를 달성한다는 연구결과를 제시했다. AI 도입은 단순한 ‘Plug and Play’ 방식이어서는 안되며, 아래와 같은 혁신 요소들을 해결해야한다고 설명했다.
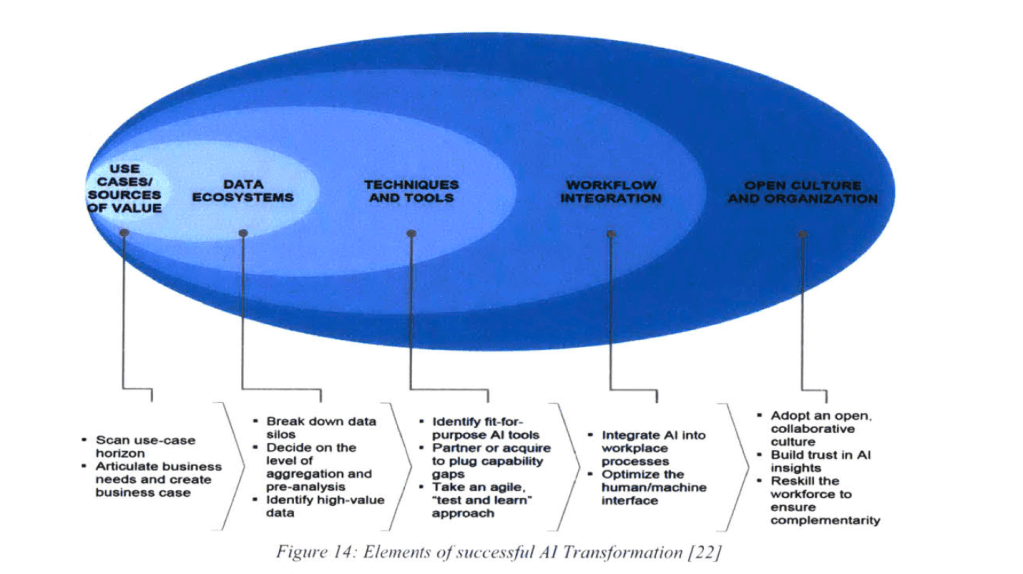
또한 Pitchbook에 따르면 머신러닝 기반 스타트업 중 10%만이 해당 시점에 머신러닝 자체를 수익을 창출하는 핵심 비즈니스로 간주하고 있었고, AI를 밸류체인 전반에 도입한 기업이 거의 없었다.
금융업의 경우 비용 절감, 리스크 관리, 생산성 향상 등을 위해 AI를 활용하고 있다. 프론트오피스의 업무 환경 개선, 신용품질 접근 및 대출 의사결정, 보험 고위험 사례 식별, 백오피스 업무 개선 등 적용 범위가 다양하다. 컴플라이언스 업무에도 활용된다.
본론: 벤처캐피탈 업계에서의 인공지능 도구와 기법 활용에 따른 기회와 위험
저자는 딜소싱, 투자기업 선정, 밸류에이션, 회수, 딜 구조, 사후관리, VC 내부의 조직, VC 외부 조직 등 8개의 밸류체인 범위에 걸쳐서 의사결정을 분석하고, 인공지능이 벤처캐피탈의 의사결정에 미치는 영향을 분석했다.
여기서 저자가 정의한 딜 구조(deal structure)는 투자자가 통제권을 가질 수 있도록 소유권을 정의하는 계약 구조를 의미한다. 사후관리는 포트폴리오 모니터링, 지원과 관리에 해당한다. VC 내부 조직이란 VC의 직원, 파트너, 그들이 특정 업무에 할애하는 시간등을 의미하며 개별 심사역의 전문화 정도 등이 이에 포함된다. VC 외부 조직이란 LP와의 관계 등을 의미한다. (다른 건 당연해서 생략)
이러한 정의를 통해 8가지 가치사슬 영역에 대한 의사결정 시나리오를 구성하고, 이에 따른 AI 자동화 적합성을 분석했다. 각 가치사슬에 대한 점수와 판단은 Rubric 기준을 기반으로 했다.

연구결과 8개 항목중 딜 선정에서 가장 높은 실현 가능성을, 딜 구조화에서 가장 낮은 실현 가능성이 있다고 나타났다.
그외 연구에서는 VC가 AI를 활용할만한 분야에 대해서 소개했는데, 그 내용은 아래와 같다. (조금 뻔하지만 2018년 연구임을 감안해야하고 그렇게 생각해도 이 업계에서는 아주 새롭지는 않지만 석사학위 논문인 것을 참조)
- SNS 프로필을 파싱/분석해 창업가의 프로필 구축
- 전문적인 네트워크 관리
- 창업팀 평가
- 신디케이트 파트너 선정
- C레벨 채용
- 포트폴리오 구성 딜소싱을 위한 최신 정보 추적 및 분석
- 신규시장 파악
또한 VC의 업무에 AI 기술이 도입되면 여러 리스크를 줄일 수 있을 뿐만 아니라, 네트워크 편향과 유사성 편향, 젠더 편향을 줄일 수 있다고 언급한다. 이는 앞서 살펴본 Data-driven VC landscape에서 언급된 내용과도 일맥상통한다.
한편 리스크로는 풍부한 데이터 셋의 부족, VC 업에서 AI를 도입하는 데에 대한 기존 VC의 저항, 사내에 AI 역량 구축의 어려움, 투자 의사결정에 AI를 도입하는 것에 대한 검증 결과가 정확하지 않다는 점, 법적 이슈, 네트워크에 대한 과도한 의존 등이 있다고 언급했다.
연구에서 진행된 인터뷰
정량적 분석 뿐만 아니라 의사결정에 AI/데이터 분석도구와 기법을 실험 중이거나 사용하는 VC와의 인터뷰도 진행했다. 주요 인사이트는 다음과 같다.
- Hone Capital: Crunchbase, Pitchbook, Mattermark 등에서 가져온 데이터베이스를 통해 ML 모델 구축. 거래당 400개의 특성을 탐색해 향후 성공 가능성을 예측할 수 있는 시드 투자 특성 확인. ML 모델은 총 투자규모, 다른 투자자의 과거 투자 전환율, 창업팀의 배경(다양한 대학 출신 여부), 신디케이터 파트너의 전문분야 등으로 기업 선별. 모델에 전적으로 의존하지는 않지만 모델 권장사항을 신뢰하고 사람의 판단과 제안을 조합. 자체 플랫폼을 통해 딜소싱을 위한 다양한 정보 활용, 주당 딜 프로세스가 2배로 증가, 엔젤리스트 파트너십을 통해 API를 사용해 잠재적 신디케이트 파트너와 연결
- Data Collective: AI는 법률적 제약으로 의사결정을 대체하지는 못해도 의사결정을 위한 정보를 제공하는데는 활용하기 좋음. 기존의 딜소싱 프로세스가 갖는 네트워크 편향성을 해소할 수 있음.
- Corelation Ventures: VC 투자 데이터가 충분하지 않아서 (매핑된 변수와 관련 결과에 대한 데이터) ML 모델 구축에 수년이 걸렸음. 또 공동 투자, 성과 지표등과 관련해 정확하고 편견 없는 정보를 수집하는 것도 어려움. 또한 VC 업무는 전문적인 네트워크와 관계에 의존하는 부분이 많아 인간의 의사결정을 완전히 자동화 하는 시스템을 구축하기엔 어려움
개인적으로 읽으면서 흥미로웠던 부분은 어느 VC보다도 적극적으로 모델을 구축한 VC에서 이것이 얼마나 어려운지 진술했다는 점이었다. 여러모로 적용하면 좋은 툴임에는 이견이 없겠지만 얼마나 훌륭한 모델을 구축하는지, 그리고 이것을얼마나 사용할 것인지에 대한 밸런스를 맞추는 것이 현업에서 매우 중요한 일일 듯 하다.
모델을 정교하게 구축하느라 온갖 리소스를 투입해도 결국 안되는 부분들이 있다면, 또 아주 제한적으로만 활용하게 된다면 그만한 낭비가 없다. 또 투자 성과를 수년 후에야 알 수 있는 업의 특성상 이를 도입해 투자하는 것에 대한 막연한 두려움 혹은 저항도 매우 클 것 같고, 데이터로 보이지 않는 ‘감’이 만들어내는 부분이 분명 존재하기 때문에 어느정도 프로세스에 어느정도로 활용하는 것이 최적점이 될 것인지는 깊은 고민이 필요할 것으로 보인다.

댓글 남기기